- Published on
Brunskill - Lecture 1
A high-level Overview
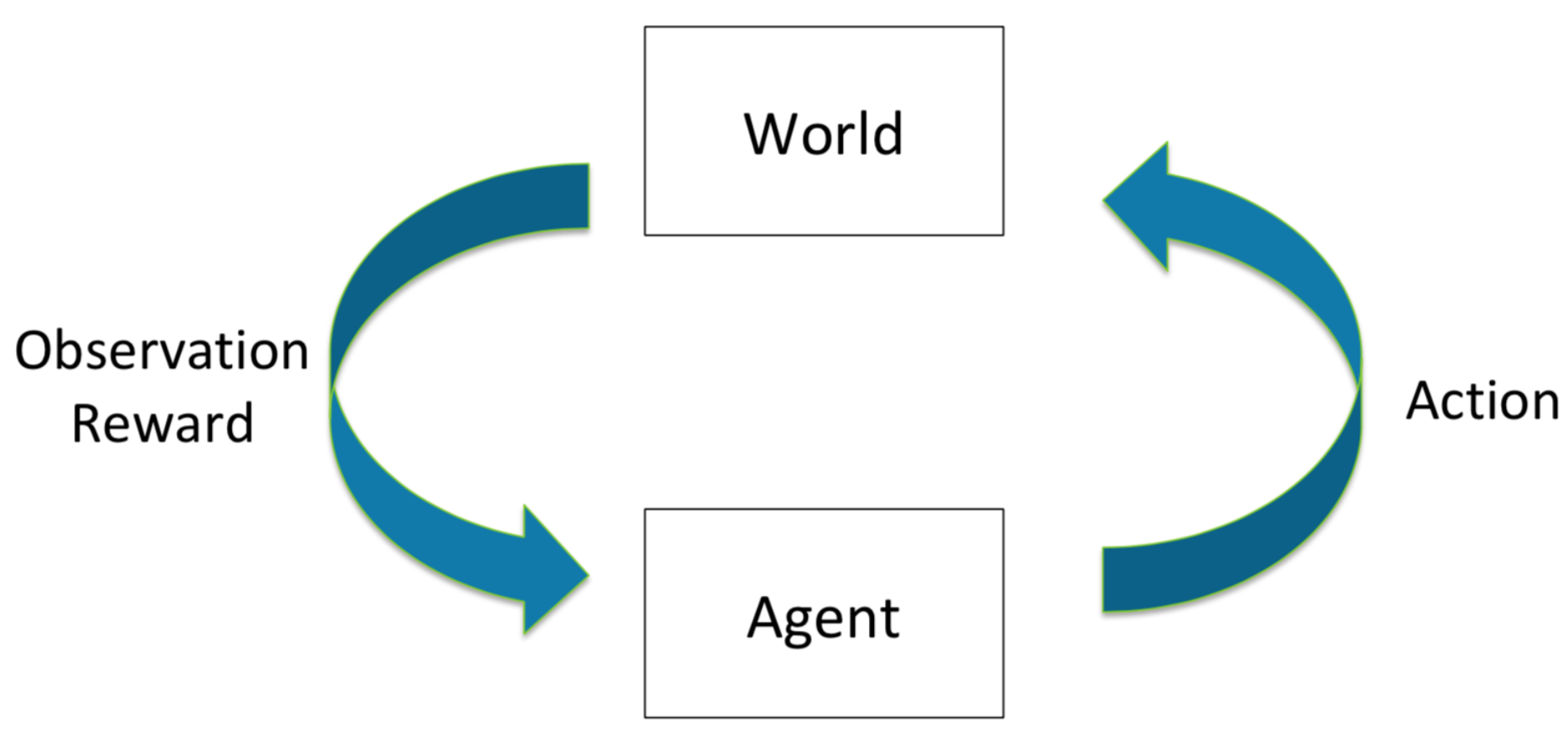 Source: Class lecture note.
Source: Class lecture note.
Examples
In the case of auction design, an agent can be the mechanism designer. An action is the choice of a particular mechanism. The world consists of a list of participants, their types, and a collection of possible outcome. Then the reward can be the resulting social welfare or the revenue.
In (auto) bidding, it is reversed. An agent is an advertiser. The world is the underlying mechanism, and possibly other advertisers. An action is a bidding strategy, and the outcome is the utility (ROI, number-of-conversions, ect.) for which this advertiser obtains.
Each (discrete) time step :
The agent makes a decision (an action) based on the history (a collection of previous actions taken, observations of the world, and rewards, if such information exists).
The world updates based on the decision.
The world outputs a reward and an observation to the agent.
Markov assumption
The new state of the world can only depends on the current state and the current action taken, without needing to look at the sequence of past states and actions. Under this Markov assumption, when making a decision, an agent only need to consider the current state.
Two models in a RL system
Dynamics model: predicts the next state, .
Reward model: predicts the immediate reward, .
A policy
A function an agent uses to maps states to actions. Could be either deterministic or stochastic.
Markov Reward Process (MRP)
A Markov chain + rewards
A set of states.
A transition model
A reward model .
A discount factor .
No actions in a MRP
Horizon
Defined as the number of time steps in each episode. Can be infinite.
Return for a Markov reward process
A random variable representing the discounted sum of rewards from time to the end of an episode. Defined as . Note that the return is defined w.r.t. a time step, not a state.
The state value function
The expected return from starting in a state , . Note that the value function is defined w.r.t. a state, not a time step.
Where does the randomness come from
So far, it seems that there are three possible sources:
The environment (often assumed to be Markov)
The policy, if stochastic
The reward function itself can also be randomized
What does a learning agent know in general
The current observed state, which may or may not fully describe the current environment. Also the history of observed states.
The immediate reward value.
What actions the agent can take (the action space).
Generally does not know the followings:
How the environment works (e.g., the transition matrix).
The reward function.
An optimal policy.